Qi Zhu
Table of Contents
Quick Links

|
Applied Scientist Bedrock Core Science AWS AI/ML Services & Infrastructure Email: qi.zhu.ckc@gmail.com Bio Currently, I am an Applied Scientist at AWS Bedrock, working on data-driven optimization of large language models (LLMs). Over the last two years, I contributed to pioneering AI systems for structured data (GraphStorm, GraphRAG) utilizing structured knowledge for applications in retrieval-augmented generation (RAG), graph machine learning, and beyond. I obtained my Ph.D. in Computer Science from University of Illinois at Urbana-Champaign advised by Prof. Jiawei Han, where I was a member of Data and Information Systems Laboratory (DAIS) and Data Mining Group. Here is my CV (outdated). |
Research
My current and past work focuses on the following themes:
- Faithful Multi-Modal Optimization for small LLMs – Addressing the reasoning gap and hallucination bottlenecks in small LLMs. We investigate how to leverage real-world usage patterns and data-driven optimization to build highly calibrated, faithful, and reliable multi-modal models without relying on massive compute.
- LLMs with Structured Knowledge – Harnessing explicit and implicit data structures to to enhance LLM reasoning capabilities and mitigate hallucinations
- Graph Representation Learning – Representing objects in heterogenous text-attributed graph with heterogenous learning, and robust to distribution shift.
I. Faithful Multi-Modal Optimization for small LLMs
Depite being edge computable, small language models (SLMs) often suffer from reasoning gaps and hallucinations, which can significantly impact their performance and reliability in real-world applications. We applied various methods to improve the grounding, faithfulness and reliability of these models including test-time scaling, post-training etc.

- Tabular Referencing Error: Addressing the pervasive "data referencing errors" (DREs) where compact models miscite, confuse, or omit table values despite parsing the structure correctly. Supported by our recent ACL work, we introduce specialized critic modules optimized via Reinforcement Learning with Verified Reward (RLVR) to significantly enhance the test-time scaling and faithfulness of 7B to 20B parameter models on data-intensive tasks.
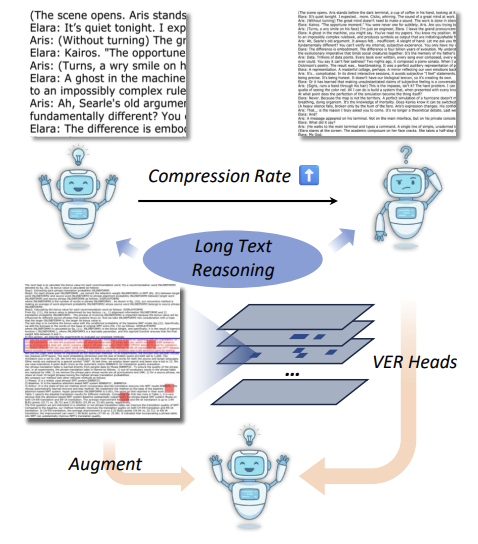
- Mechanistic Interpretability and Retrieval Dynamics in Long-Context VLMs: Investigating the internal processing bottlenecks of Vision-Language Models handling dense, text-rich image documents. Supported by our recent work introducing VERA, we discover Visual Evidence Retrieval (VER) heads—a sparse, dynamic set of attention heads critical for locating visual cues during high-uncertainty reasoning steps. We leverage these mechanistic insights to design training-free, inference-time interventions that mitigate the visual-textual attention imbalance and significantly boost long-document comprehension.
II. LLMs with Structured Knowledge
We aim to make LLMs more efficient and resilient against hallucinations by harnessing structured knowledge. A key challenge lies in making the language model structure-aware while mitigating performance bottlenecks, such as the lost-in-the-middle phenomenon, To address this, we explore fine-tuning, and pre-training techniques on graph structured data. [SURGeLLM, ACL 2026] [Structured Knowledge for LLMs, KDD 2025]
- Graph Retrieval Augmented Generation: We propose HYBGRAG, an agentic system for hybrid question answering over semi-structured knowledge bases. Unlike prior RAG systems that handle only textual or relational information, HYBGRAG synergizes both through a retriever bank with adaptive module selection and a critic module that provides corrective feedback for iterative refinement. This structure-aware approach addresses the lost-in-the-middle phenomenon by precisely routing questions to appropriate retrieval modules and self-correcting extraction errors.
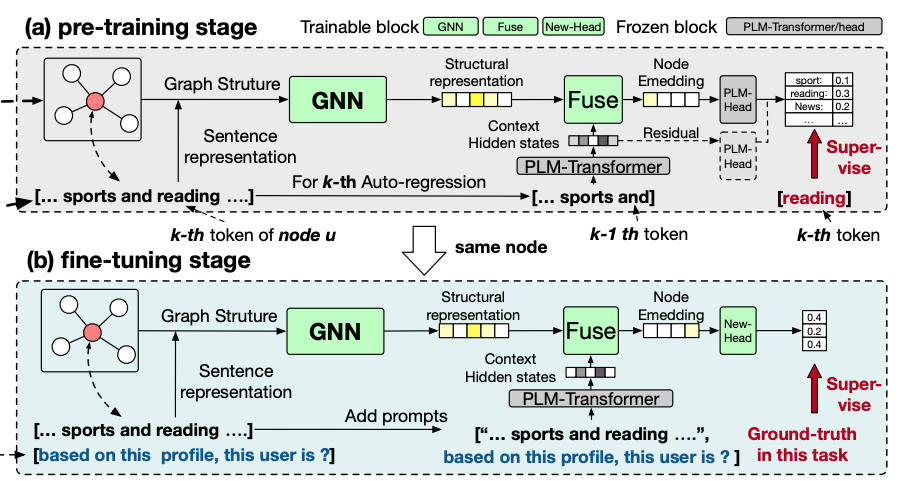
- Supervised Fine-tuning LLMs on graphs: We propose parameter-efficient fine-tuning of billion-scale GNN-LLM architecture to align the latent space between structure and text. The goal is to better adapt LLMs on graph representation learning with small of computation resources.
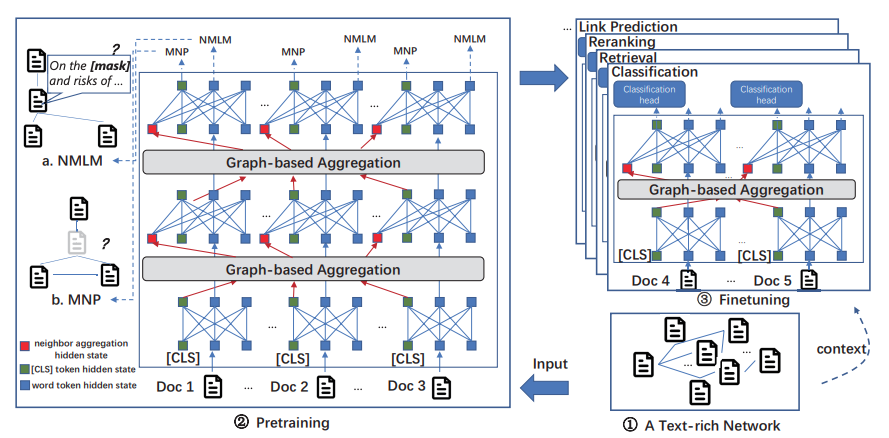
- Pre-training Cascading GNN-LM: Numerous real-world application can be modeled as a text-attributed graph such as citation network and social network, where nodes or edges contains useful text information. We pre-train million-scale language model with GNN layers interleaved in transformers.
III. Graph Representation Learning
My research aims to make graph representation learning adapt to distribution shift and data heterogeneity.
- GNN Out-of-distribution Generalization:
Graph neural networks are notoriously poor at generalizing to out-of-distribution target data.
We conduct theoretical analysis of their generalization properties and introduce unsupervised loss between training and target distributions to enhance robustness and performance on unseen data.
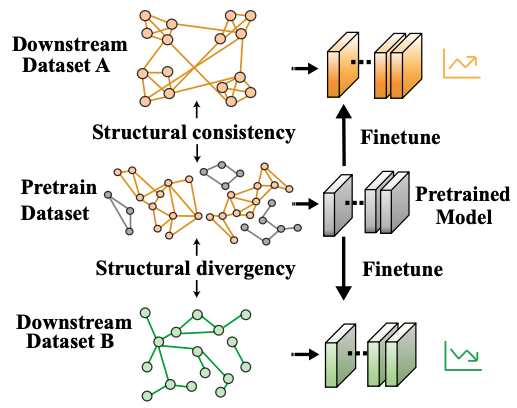
- Fine-Tuning Graph Neural Networks by Preserving Graph Generative Patterns, AAAI'24
- May the Force be with You: Unified Force-Centric Pre-Training for 3D Molecular Conformations, NeurIPS'23
- Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data, NeurIPS'21
- Transfer Learning of Graph Neural Networks with Ego-graph Information Maximization, NeurIPS'21
- Heterogenous Graph Representation Learning:
Awards
- 2020 Amazon AWS Machine Learning Research Award
- 2018 ACM WWW Best Poster Honorable Mention