Integrating Local Context and Global Cohesiveness for Open Information Extraction
Updates
2018.8 ReMine supports our KDD showcase demo AutoNet!
2018.7 ReMine’s backend migrates from Stanford NLP to Spacy.
2018.3 ReMine 0.1 release!
Task Overview
Extracting entities and their relations from text is an important task for understanding massive text corpora. Open information extraction (IE) systems mine relation tuples <head entity, predicate, tail entity>(i.e., entity arguments and a predicate string to describe their relation) from sentences. These relation tuples are not confined to a predefined schema for the relations of interests. However, current Open IE systems focus on modeling local context information in a sentence to extract relation tuples, while ignoring the fact that global statistics in a large corpus can be collectively leveraged to identify high-quality sentence-level extractions.
Our Method
To address the above issues, we propose a novel Open IE system, called ReMine, which integrates local context signals and global structural signals in a unified, distant-supervision framework. Leveraging facts from external knowledge bases as supervision, the new system can be applied to many different domains to facilitate sentence-level tuple extractions using corpus-level statistics.
- We develop a context-dependent phrasal segmentation algorithm that can identify high quality entity and relation phrases.
- Instead considering only local context information, we design a unified objective to measure both tuple quality in a local context and global cohesiveness of candidate tuples. Extensive experiments show superior performance on entity phrase extraction task as well as Open IE task.
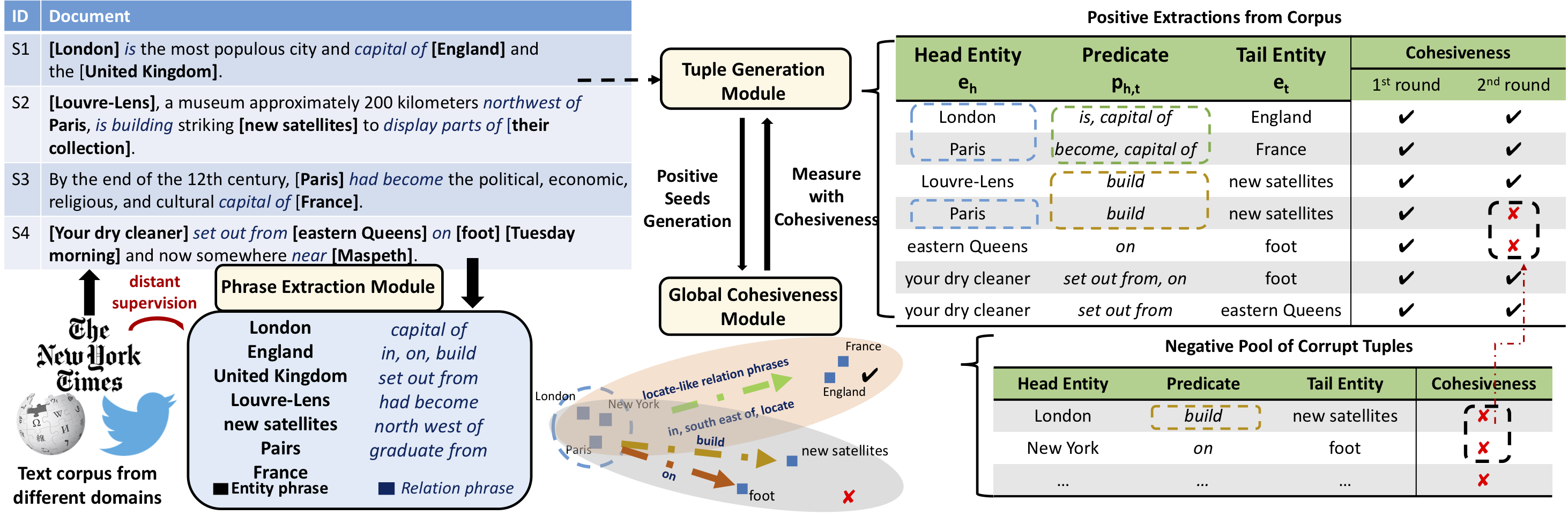
Framework
-
Phrase extraction module trains a robust phrase classifier using existing entity phrases from external knowledge base as “distant supervision” and adjust quality iteratively.
-
Tuple generation module: generates candidate tuples based on sentence’s language structure—it adopts widely used local structure patterns. Different from previous studies, the module incorporates corpus-level information redundancy(global cohesiveness).
-
Global Cohesiveness module: learns entity and relation phrase representation and uses the representation in a score function to rank tuples.
-
Iteratively update sentence-level extractions based on both local context information and global structure cohesiveness.
Performance
We evaluated our model on two domains: NYT and Twitter, each extraction in the mixed extraction pool is annotated by two annotators independently.
The table includes performance comparison with several Open IE systems over NYT corpus (sentence-level extraction):
| Methods | Precision@100 | Precision@200 | MAP | NDCG@100 | NDCG@200 |
|---|---|---|---|---|---|
| ClausIE (Luciano et al., 2013) | 0.580 | 0.625 | 0.623 | 0.575 | 0.667 |
| Stanford (Angeli et al., 2015) | 0.680 | 0.625 | 0.665 | 0.689 | 0.654 |
| OLLIE (Mausam et al., 2012) | 0.670 | 0.640 | 0.683 | 0.684 | 0.775 |
| MinIE (Gashteovski et al., 2017) | 0.680 | 0.645 | 0.687 | 0.724 | 0.723 |
| ReMine | 0.780 | 0.720 | 0.760 | 0.787 | 0.791 |
Resources
- Codes and datasets have been uploaded to Github
- Live demo on News and Bio corpus.
- ReMine-server will start a local server, access ReMine by inputing https://localhost:port-number in browser.
- ReMine-standalone is the standalone command line version for testing and training on given corpus.